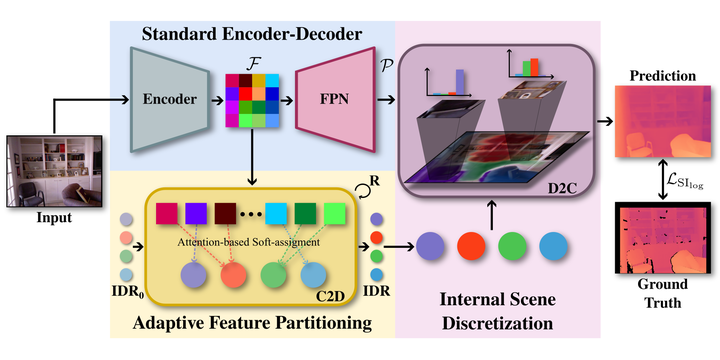
TL;DR
Abstract
Monocular depth estimation is fundamental for 3D scene understanding and downstream applications. However, even under the supervised setup, it is still challenging and ill-posed due to the lack of full geometric constraints. Although a scene can consist of millions of pixels, there are fewer high-level patterns. We propose iDisc to learn those patterns with internal discretized representations. The method implicitly partitions the scene into a set of high-level patterns. In particular, our new module, Internal Discretization (ID), implements a continuous-discrete-continuous bottleneck to learn those concepts without supervision. In contrast to state-of-the-art methods, the proposed model does not enforce any explicit constraints or priors on the depth output. The whole network with the ID module can be trained end-to-end, thanks to the bottleneck module based on attention. Our method sets the new state of the art with significant improvements on NYU-Depth v2 and KITTI, outperforming all published methods on the official KITTI benchmark. iDisc can also achieve state-of-the-art results on surface normal estimation. Further, we explore the model generalization capability via zero-shot testing. We observe the compelling need to promote diversification in the outdoor scenario. Hence, we introduce splits of two autonomous driving datasets, DDAD and Argoverse.
Qualitative Results
Visualizations of the proposed method on test sequences. These are neither cheery-picked nor post-processed in any way.
Pointcloud visualization
Examples of running iDisc on test images. We show RGB pointclouds and error-wise color-coded pointclouds. There red corresponds to higher errors, up to 0.5m for NYUv2 and 2m for KITTI, and blue corresponds to lower error.
NYU-Depth v2
Results of iDisc trained on NYU-Depth v2. The model ingests the RGB image (top-left) and outputs depth and surface normals predictions (bottom). We show 4 different attention maps coming from 4 different IDRs, two at lowest, one at middle and another at highest resolution. Attention maps artifacts come from the upsampling process, while the flickering effect is due to the high framerate (30fps) without any smoothing.
KITTI
Results of iDisc trained on KITTI. Pointcloud visualization in a drive-through fashion. The sequence is part of the validation set. Pointcloud visualization with a little pitch angle rotation creates little Moire pattern artifacts in areas corresponding to groud points.
BibTex
@InProceedings{piccinelli2023idisc,
author = {Piccinelli, Luigi and Sakaridis, Christos and Yu, Fisher},
title = {iDisc: Internal Discretization for Monocular Depth Estimation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {21477-21487}
}
Luigi Piccinelli
PhD student in Computer Vision
My research interests include 3D Vision and more broadly Artificial Intelligence.